token-optimizer
Claude Code token optimizer plugin — identifies and fixes token waste across context, skills, and memory, with a live dashboard
This Claude Code plugin provides comprehensive token optimization by identifying and fixing structural token waste in CLAUDE.md, unused skills, and stale memory, alongside runtime command output. It offers a fully local, zero-dependency live dashboard that tracks per-turn token breakdown, costs, cache analysis, and quality scores without consuming context tokens. The plugin also checkpoints sessions before compaction, restoring context to prevent degradation and providing real-time savings tracking.
- Live HTML dashboard for per-turn token breakdown and costs
- Identifies structural waste: unused skills, duplicate configs, stale memory
- Checkpoints sessions before compaction, restores context after
- Zero context tokens consumed; runs as an external, local process
- Tracks quality scores, subagent costs, skill adoption, and model mix




README
View on GitHub ↗
![]()
![]()


![]()
Your AI is getting dumber and you can't see it.
Save tokens. Survive compaction. Measure the proof.
Most token tools only touch one slice of the problem.
They compress command output, which covers 15-25% of your context on a good day. The other 75-85% (bloated configs, unused skills, duplicate system prompts, stale memory, plus the 60-70% you lose on every compaction) goes untouched.
Token Optimizer covers all of it, keeps your work alive across compactions, measures whether the optimization actually helped, and gives you a live dashboard that shows every token, every dollar, and every turn, auto-updated after every session. Runs fully local. Zero context tokens used. Zero runtime dependencies.
Works on Claude Code and OpenClaw today. Windsurf, Cursor, and more on the way.

Install
Recommended on every platform (macOS, Linux, Windows):
/plugin marketplace add alexgreensh/token-optimizer
/plugin install token-optimizer@alexgreensh-token-optimizer
Then in Claude Code: /token-optimizer
Please enable auto-update after installing. Claude Code ships third-party marketplaces with auto-update off by default, and plugin authors cannot change that default. So you won't get bug fixes automatically unless you turn it on. In Claude Code:
/plugin→ Marketplaces tab → selectalexgreensh-token-optimizer→ Enable auto-update. One-time, 10 seconds, and you'll never miss a fix again. Token Optimizer also prints a one-time reminder on your first SessionStart so you don't forget.
Windows users: read this first
The plugin install above is the only path you should use on Windows. Do not also run the install.sh script described below — that's a bash installer for macOS/Linux/WSL, and combining the two creates an EBUSY: resource busy or locked error because Git Bash holds Windows file handles open while the plugin system is trying to clone.
Repo size note: our repo is ~3 MB (218 files, ~2,700 git objects). If your /plugin marketplace add attempt seems to be downloading gigabytes, it's not us — cancel and check whether Claude Code is cloning a different URL or network state. You can verify by cloning manually: git clone --bare https://github.com/alexgreensh/token-optimizer.git should finish in under a second and produce a ~2.6 MB directory.
If you've already hit the EBUSY error:
- Close every Claude Code window and Git Bash terminal.
- Open Task Manager and end any lingering
git.exeprocesses. - Delete both folders if they exist:
C:\Users\<you>\.claude\token-optimizerC:\Users\<you>\.claude\plugins\marketplaces\alexgreensh-token-optimizer
- If Windows still refuses to delete (file in use), reboot, then delete.
- Open a fresh Claude Code window and run the two
/plugincommands above.
Manual ZIP fallback (if plugin install repeatedly fails): download the repo ZIP (~800 KB), extract to C:\Users\<you>\.claude\token-optimizer\, then run python measure.py setup-quality-bar from that directory. Note: on Windows the command is python, not python3.
macOS / Linux only: script install (alternative)
If you prefer a script-managed install on macOS or Linux, this works too and auto-updates daily via git pull --ff-only. Do not run this on Windows, and do not run it alongside the plugin install above on any platform. Pick one method.
git clone https://github.com/alexgreensh/token-optimizer.git ~/.claude/token-optimizer
bash ~/.claude/token-optimizer/install.sh
Works on Claude Code and OpenClaw. Each platform has its own native plugin (Python for Claude Code, TypeScript for OpenClaw). No bridging, no shared runtime, zero cross-platform dependencies.
Full Visibility: See Every Token, Every Dollar, Every Turn
Most tools tell you your context is full. Token Optimizer shows you exactly where every token went, how much each turn cost, which skills and MCP servers actually fired, and which ones are just sitting there eating your budget.
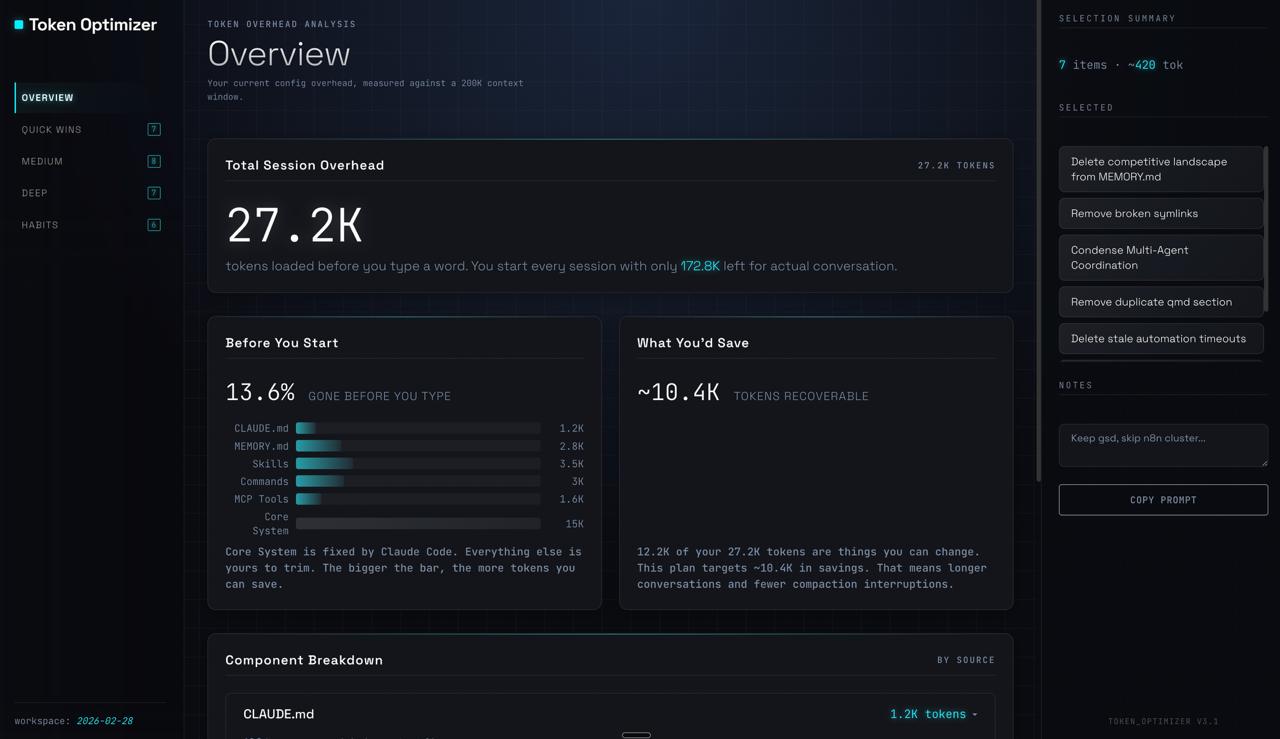
One single-file HTML dashboard. Auto-regenerates after every session via the SessionEnd hook. Bookmark http://localhost:24842/token-optimizer and it's always current. Zero tokens from your context, zero network calls, zero setup after install.
What the dashboard tracks
- Per-turn token breakdown for every API call: input, output, cache-read, cache-write, with spike detection highlighting context jumps
- Cache analysis: stacked bars showing input vs output vs cache-read vs cache-write split, with TTL mix (
1hvs5m) and hit rate alongside - Pacing metrics between calls so you can see whether a thread was steady or stop-start
- Cost across 4 pricing tiers: Anthropic API, Vertex Global, Vertex Regional, AWS Bedrock. Set your tier once and every session updates
- Color-coded quality scores overlaid on every session: green healthy, yellow degrading, red trouble
- Subagent cost breakdown: orchestrator vs worker spend, top offenders ranked by cost, flags when subagents consume over 30%
- Top 5 costliest prompts per session, pairing each user message with the cost of the response
- Skill adoption trends: which skills you actually invoke vs just having installed
- Model mix over time: Opus, Sonnet, Haiku breakdown across every session
- CLAUDE.md and MEMORY.md health cards on the Overview tab with line count, orphan count, and status at a glance
- Drift detection: config snapshots compared across time so you catch creep before it costs you
- Savings tracker: cumulative dollars saved from optimizations, checkpoint restores, and archives
/context shows a capacity bar. Proxy compressors print a terminal report. Token Optimizer shows the receipts, auto-updated, at zero context cost.
Launch it
python3 measure.py setup-daemon # Bookmarkable URL at http://localhost:24842/token-optimizer
python3 measure.py dashboard --serve # One-time serve over HTTP
Throughout this README, whenever a feature mentions it's also visible on the dashboard, that means it lives inside this same HTML page. One place, everything tracked.
What Makes This Different
Two kinds of token waste, and most tools only fix one
Runtime waste: verbose command output that floods your context. Covers maybe 15-25% of what you're burning. This is what proxy compressors handle.
Structural waste: bloated CLAUDE.md, unused skills, duplicate system reminders, stale MEMORY.md, invisible entries past line 200, dead MCP servers. Covers the other 75-85%. Almost nobody touches this.
Token Optimizer handles both. And because it also checkpoints your session before compaction fires and restores what the summary dropped, the savings actually stick instead of vanishing the moment auto-compact kicks in.
Fully local, zero dependencies, zero telemetry
Pure Python stdlib on Claude Code. Pure Node stdlib on OpenClaw. Nothing to pip install, nothing to npm install at runtime, no analytics endpoint, no phone-home. Every measurement is a local SQLite write to a file you own at ~/.claude/_backups/token-optimizer/trends.db. You can inspect it, export it, or delete it.
Zero context tokens consumed
Token Optimizer runs as an external process. It doesn't inject instructions into your context, it doesn't add MCP overhead, and it never eats into your window. Your full 1M budget stays fully yours.
/context shows the dashboard light. Token Optimizer opens the hood.
/context tells you that your context is 73% full. Token Optimizer tells you which 12K are wasted on skills you never use, flags 47 orphaned MEMORY.md topic files Claude can't see, checkpoints your decisions before compaction destroys them, and gives you a quality score that tracks how much dumber your AI is getting as the session wears on.
Real Savings
One real snapshot from 30 days of heavy Opus use: 942 sessions, 6.13B input tokens, 90% Opus, 82% cache hit rate.

$1,500 to $2,500 per month for a heavy user at these volumes. Input savings alone come to around $590. The rest is output and thinking tokens saved by catching loops, landing /compact at the right moment, and avoiding rebuilds after bad compactions.
Lighter users see proportional savings. Structural audit wins (unused skills, duplicate configs, orphaned memory entries) are immediate regardless of volume, and they compound because a smaller prefix means a smaller cache-read bill on every single turn that follows.
Trust & Safety FAQ
🎯 Can Token Optimizer degrade my context quality?
No. Structural optimization only removes genuinely unused components (skills you never invoke, duplicate configs, orphaned memory entries). Active Compression features are independently toggleable, and the lossy ones (like Bash Compression) can be disabled with a single command or env var. The 7-signal quality score actively tracks degradation, so if anything ever hurt quality, the score would show it.
💾 Does it break the prompt cache?
No, and this matters. The prompt cache depends on a stable prefix. Any tool that edits or removes blocks already in your conversation invalidates the cache and costs you more, not less.
Token Optimizer never touches content that's already in your context. It works on new content entering your window (compression), and on what happens before and after compaction (checkpoints and restore). Your cache prefix stays intact, which means Token Optimizer actually saves you money twice:
- Less input per turn. Fewer structural tokens means a smaller context, so every message processes faster and cheaper.
- Cheaper cache reads on every turn forward. A smaller stable prefix means a smaller cache-read bill on every subsequent message. This compounds across the session.
Be careful with tools that claim to "clean up" your context mid-session. If they modify or remove existing conversation blocks, they break your cache. The cost of re-sending a full prefix at uncached rates on the next 50 messages easily wipes out whatever they saved you.
🔒 Does it send any data anywhere?
No network calls. No analytics. No opt-out telemetry because there's nothing to opt out of. Every event is a local SQLite row. You can sqlite3 it, export it, delete it, or never look at it. It's yours.
🛟 Can it hurt my session?
No. All hooks are non-blocking with fail-open design. If a Token Optimizer script ever errors, your command runs normally. Compression features are all individually toggleable. Checkpoints are additive. Quality scoring is read-only measurement.
📦 Does it have any runtime dependencies?
No. Pure Python stdlib on Claude Code. Pure Node stdlib on OpenClaw. Nothing to pip install, nothing to npm install at runtime. What you clone is everything it needs.
🧰 Which platforms does it support?
Claude Code and OpenClaw today, with native plugins for each (Python for Claude Code, TypeScript for OpenClaw, no shared runtime, no cross-platform bridging).
Windsurf and Cursor are next on the roadmap. Codex is waiting for the plugin API to stabilize.
Why install this first
Every Claude Code session starts with invisible overhead: system prompt, tool definitions, skills, MCP servers, CLAUDE.md, MEMORY.md. A typical power user burns 50-70K tokens before typing a word.
With Opus 4.6 and Sonnet 4.6 now at 1M context, that feels like breathing room. The problems still compound:
- Quality degrades as context fills. MRCR drops from 93% to 76% between 256K and 1M. Your AI gets measurably dumber as the window fills.
- Rate limits hit faster. Ghost tokens count toward your plan's usage caps on every message, cached or not. 50K overhead times 100 messages is 5M tokens burned on nothing.
- Compaction is catastrophic. 60-70% of your conversation gone per compaction. After 2-3 compactions, you've lost 88-95%. And each compaction means re-sending all that overhead again.
- Higher effort means faster burn. More thinking tokens per response means you hit compaction sooner, which means more total tokens across the session.
- You can't fix what you can't see. Without per-turn visibility into cache hits, model mix, and subagent spend, every "it feels slow" guess costs money. The dashboard shows exactly which turn was the expensive one.
Token Optimizer tracks all of this. Quality score, degradation bands, compaction loss, drift detection, per-turn cost across four pricing tiers, and skill-and-MCP attribution for every session. Zero context tokens consumed.

"But doesn't removing tokens hurt the model?" No. Token Optimizer only touches what's safe to touch. Structural optimization removes genuinely unused components (duplicate configs, unused skill frontmatter, orphaned memory entries), never the conversation itself. Active Compression works on new content entering your window (smart re-reads, credential-safe command summaries) and on the compaction boundary (checkpoints before auto-compact, restore after). Nothing already in your context gets edited or removed, which means your prompt cache stays intact. The 7-signal quality score tracks degradation in real time, and most users see scores improve after optimization because the model has more room for real work.
Smart Compaction and Session Continuity
When auto-compact fires, 60-70% of your conversation vanishes. Decisions, error-fix sequences, agent state, all gone.
Smart Compaction catches all of it as checkpoints before compaction fires, then restores what the summary dropped. It also injects a digest of large tool outputs the model previously processed, so after compaction the model knows what it already saw without re-reading everything from scratch. Sessions pick up where you left off, even after a crash or /clear. Checkpoint history and compaction loss per session are also visible on the dashboard.
Compression savings only stick if your session survives the compaction. Saving tokens on git status doesn't help if the next auto-compact wipes out the decision that made you run git status in the first place. Smart Compaction closes that loop: checkpoint your decisions, restore them after compaction, and remind the model what outputs it already processed so it doesn't waste tokens re-reading them.
python3 measure.py setup-smart-compact # checkpoint + restore hooks
Progressive Checkpoints
Instead of waiting for emergency compaction, Token Optimizer captures session state at multiple thresholds: 20%, 35%, 50%, 65%, and 80% context fill, plus quality drops below 80, 70, 50, and 40. It also snapshots before agent fan-out and after large edit batches. On restore, it picks the richest eligible checkpoint, not just the most recent one.
Background guards handle one-shot threshold capture, cooldown suppression, and deterministic extraction. No LLM calls in the checkpoint path.
Tool Result Archive (model-aware, no manual lookups)
Large tool results (>4KB) get archived to disk automatically. In your conversation, the full result is replaced with a short preview plus an inline hint like [Full result archived (12,400 chars). Use 'expand abc123' to retrieve.]
That hint is visible to Claude, not just you. So after a compaction (when the original tool result has been summarized away), if the model needs the full output again to answer your next question, it invokes expand abc123 itself and the archived content comes back through the CLI. No command re-run, no lost output, no context cost in the meantime.
You can run expand yourself too when you want to see a specific archived result, but the primary flow is automatic: the model sees the hint, the model asks for the bytes, the bytes come back.
python3 measure.py expand --list # List all archived tool results
python3 measure.py expand <tool-use-id> # Retrieve a specific archived result manually
Session Continuity
Sessions auto-checkpoint on end, /clear, and crashes. On a fresh session, Token Optimizer drops a short in-context pointer to the most recent relevant checkpoint, so Claude can pull the right prior state on its own if the new conversation needs it. No auto-replay of stale context, no user action required, just a breadcrumb the model can follow when it matters.
Enable optional local-only checkpoint telemetry to see whether checkpoints are firing and which triggers are active:
TOKEN_OPTIMIZER_CHECKPOINT_TELEMETRY=1 python3 measure.py checkpoint-stats --days 7
Quality Scoring
Seven signals, weighted to reflect real-world impact:
| Signal | Weight | What It Means For You |
|---|---|---|
| Context fill | 20% | How close are you to the degradation cliff? Based on published MRCR benchmarks. |
| Stale reads | 20% | Files you read earlier have changed. Your AI is working with outdated info. |
| Bloated results | 20% | Tool outputs that were never used. Wasting context on noise. |
| Compaction depth | 15% | Each compaction loses 60-70% of your conversation. After 2, 88% is gone. |
| Duplicates | 10% | The same system reminders injected over and over. Pure waste. |
| Decision density | 8% | Are you having a real conversation, or is it mostly overhead? |
| Agent efficiency | 7% | Are your subagents pulling their weight or just burning tokens? |
Efficiency Grades
Every quality score includes a letter grade for quick triage. The status line shows something like ContextQ:A(82), and the same grade appears in the dashboard, coach tab, and CLI output.
| Grade | Range | Meaning |
|---|---|---|
| S | 90-100 | Peak efficiency. Everything is clean. |
| A | 80-89 | Healthy. Minor optimization possible. |
| B | 70-79 | Degradation starting. Worth investigating. |
| C | 60-69 | Significant waste. Coach mode will help. |
| D | 50-59 | Serious problems. Multiple anti-patterns likely. |
| F | 0-49 | Context is rotting. Immediate action needed. |
Degradation Bands
The status bar shifts color as your context fills:
- Green (<50% fill): peak quality zone
- Yellow (50-70%): degradation starting
- Orange (70-80%): quality dropping
- Red (80%+): severe, consider /clear
What Degradation Actually Looks Like
Real session. 708 messages, 2 compactions, 88% of the original context gone. Without the quality score, you'd have no idea.

Active Compression (v5)
Token Optimizer no longer just measures context bloat. It actively reduces it. Seven features target specific waste patterns, each with honest risk assessment and dashboard toggles.

On by default: Quality Nudges, Loop Detection, Delta Mode, Structure Map, Bash Compression (16 handlers), Activity Mode Detection, Decision Extraction.
All features are independently toggleable from the Manage tab in the dashboard, via CLI (measure.py v5 enable|disable <feature>), or with environment variables.
| Feature | Default | Potential Savings | Risk |
|---|---|---|---|
| Quality Nudges | ON | Measured per-compact (fill% recovery) | None |
| Loop Detection | ON | Measured per-loop (actual turn content) | None |
| Delta Mode | ON | ~20% (smart re-reads) | Low |
| Structure Map | ON (soft-block) | ~30% (large file re-reads, up to 99% per file) | Low |
| Bash Compression | ON | ~10% (CLI output) | Low |
| Activity Mode | ON | Adapts compaction to session phase | None |
| Decision Extraction | ON | Preserves decisions across compactions | None |
Privacy note: Every feature runs 100% on your machine. Nothing is ever sent anywhere. No analytics endpoint, no phone-home, no cloud sync. "Measurement" and "beta telemetry" always mean local-only SQLite writes to a file you own, and you can inspect, export, or delete that file at any time. Token Optimizer has zero network calls by design.

Quality Nudges (ON by default, fully automatic)
Watches your context quality in real time. When the score drops 15+ points or crosses below 60, an inline system note enters the context that reads something like [Token Optimizer] Quality dropped to 58. Consider /compact to protect context.
Claude sees that note on the next turn and surfaces the warning to you naturally, or adjusts behavior on its own. You don't have to watch a dashboard or remember thresholds. The nudge shows up right where decisions get made, with zero setup after install.
Value: catches context rot early so /compact lands at the right moment, before you lose decisions to compaction.
How it works: runs inside the existing quality-cache hook on every UserPromptSubmit. Cooldown of 5 minutes between nudges, max 3 per session. Suppressed on the first check after a compaction, so you don't get warned about quality you just fixed.
Risk: none. Only adds a short note to context, never removes anything.
Loop Detection (ON by default, fully automatic)
Catches the AI getting stuck on a retry loop before it burns through tokens. When similarity crosses the threshold, a short inline note lands in the context flagging the loop so the model breaks out of it, with no user action needed. Savings are measured from the actual content of the looping turns, not estimated.
Value: post-hoc detectors found that loop sessions average 47K wasted tokens. Real-time detection prevents this. Every caught loop logs the measured token cost of the loop turns to your local telemetry.
How it works: compares the last 4 user messages and last 5 tool results for similarity. Fires at confidence ≥0.7 with a session cap of 2 notes. Uses fixed message templates and never echoes user content back.
Risk: none. Only adds a short note.

Delta Mode (ON by default, your biggest single win)
When the AI re-reads a file after editing it, the Read call returns only what changed instead of the whole file. Fully automatic, no configuration, no user action. 65%+ of Read calls in real sessions are re-reads, which makes this the highest-impact v5 feature.
Value: typical sessions re-read the same file 2-5 times. Delta mode sends only the diff. A 2,000-token file re-read becomes a 50-token diff, for 97% savings on that specific read.
How it works: stores file content (up to 50KB per file) in a local cache on first read. On re-read with changed mtime, computes a unified diff via Python's difflib (stdlib, no git dependency). Falls back to full re-read if the diff exceeds 1,500 chars or either file exceeds 2,000 lines. Scoped to explicit full-file reads so narrow offset/limit requests are never served a whole-file diff. .env and credential files are excluded from caching.
Risk: low. If the AI needed the full file to understand the change in context, the diff alone might not be enough. Fails open on large changes and big files. Set TOKEN_OPTIMIZER_READ_CACHE_DELTA=0 to disable.
Structure Map (ON in soft-block mode, your biggest win on large files)
When Claude re-reads a code file it already saw this session, the Read call is blocked and replaced with a compact structural summary: function signatures, class hierarchies, imports, and module docstrings. A 720KB Python file (180,000 tokens) becomes a 250-token skeleton. Works on Python files up to 800KB/20K lines and JS/TS files up to 400KB/5K lines.
Value: code-heavy sessions re-read the same large files 3-17 times. Structure Map compresses every re-read after the first by 95-99%. On a 180K-token file re-read 5 times, that's ~900K tokens saved in a single session.
How it works: on first read, caches the file content and generates an AST-based summary (Python) or regex-based summary (JS/TS). On subsequent reads of the same unchanged file, returns the summary via additionalContext and blocks the full re-read. Falls back to full read on files below 1,000 tokens, generated/minified files, partial-range reads, or if the AST parse fails.
Measurement: enable measure.py v5 enable structure_map_beta or TOKEN_OPTIMIZER_STRUCTURE_MAP=beta to log compression events to your local SQLite for compression-stats. Nothing sent anywhere.
Risk: low. The model works from the summary instead of full source. For files where implementation details matter (not just structure), the model can request a full read. Disable with TOKEN_OPTIMIZER_READ_CACHE_MODE=shadow.

Bash Output Compression (ON by default, lossy)
Rewrites common CLI commands to return compressed summaries instead of verbose output. v5.1.0 ships seven new handlers covering the command families that eat the most context: lint (rule-code grouping for eslint, ruff, flake8, shellcheck, rubocop, golangci-lint), log tails (adjacent-duplicate collapse), tree (depth-2 truncation), docker build and pull (progress filtering), long listings (pip list, npm ls, docker ps, with top-N plus tail marker), JS/TS/Go build output (error-and-summary view), and test runner routing (cypress, playwright, mocha, karma all route through the unified pytest compressor).
Together with the existing git and pytest handlers, that's full coverage for ~90% of the verbose CLI output real sessions produce.
Value: strips hundreds of lines of test/build/git output down to just the essentials. A 564-token pytest output becomes 115 tokens. A 60-file ls -la truncates to 50. Best for sessions with lots of CLI commands.
How it works: a PreToolUse hook (bash_hook.py) intercepts safe read-only commands, tokenizes them with shlex.split(), checks against a whitelist, and rewrites them via updatedInput to route through a compression wrapper (bash_compress.py). Categorically excludes compound commands (anything with ;, &&, ||, |, $(), backticks, >, >>), sudo, and interactive flags.
Security: shell=True is never used. Credentials (AWS keys, GitHub PATs, Slack tokens, Stripe keys, OpenAI keys, HTTP basic-auth URLs) are scanned pre-compression and preserved verbatim. Multilingual error lines survive the preservation path. Partial output on timeout is returned raw, never compressed.
How to disable: measure.py v5 disable bash_compress or TOKEN_OPTIMIZER_BASH_COMPRESS=0
Risk: low. Compression is lossy by design. For routine checks this is fine. For careful diff review or debugging specific test failures, disable temporarily with the command above.
Activity Mode Detection (ON by default, v5.6)
Classifies your session into one of five modes
Similar plugins
superpowers
Claude Code plugin for agentic software development — automates TDD, planning, and subagent coordination



everything-claude-code
Claude Code plugin: agent harness performance system with skills, memory, security, and continuous learning



andrej-karpathy-skills
Claude Code plugin for LLM coding guidelines — applies Karpathy's principles to prevent common AI coding pitfalls



claude-mem
Persistent memory for Claude Code plugin — captures, compresses, and reinjects session context


